GCF vs TOON
GCF has two profiles. TOON has one. The comparison plays out on both dimensions, and GCF wins both.
On structured data (generic profile, the common case): GCF achieves 100% comprehension on every frontier model tested. TOON fails on GPT-5.5 and Gemini Flash. Both formats can encode flat tabular data, but GCF is 29% smaller across 16 real-world datasets. LLMs produce valid GCF at 5/5 on every frontier model. TOON's own decoder rejects LLM-generated output on 7 of 9 models.
On relationship data (graph profile): TOON has no grammar for this. No local IDs, no edge notation, no session dedup, no distance grouping. TOON must repeat full identifiers on every edge (~30-100 tokens each). GCF uses @0<@1 calls (~4 tokens). On 500-symbol code graphs, GCF scores 91.2% comprehension. TOON scores 68.8%. This isn't a gap that closes with optimization. TOON structurally cannot represent relationships efficiently without becoming a different format.
On TOON's own benchmark: We forked their benchmark, ran their original 6 datasets with their tokenizer and methodology, then added 9 more representing real-world MCP tool responses. GCF wins 15 of 16 overall. TOON's one win is 77 tokens on a single dataset. Across all 16 datasets GCF uses 218,529 fewer tokens than TOON (29% less).
Feature comparison
| Feature | GCF | TOON |
|---|---|---|
| Tabular encoding (arrays of objects) | Yes | Yes |
| Positional fields (no field names per row) | Yes | Yes |
| Pipe-separated rows | Yes | Comma-separated |
| Nested object encoding | ## key sections + key=value | Indented key: value |
| Semi-uniform data (optional fields) | Native (inline nested when present) | Falls back to less efficient encoding |
| Local IDs for cross-referencing | Yes (@0, @1) | No |
| Edge/relationship encoding | Yes (@0<@1 calls, ~4 tokens/edge) | No (must repeat full identifiers, ~100 tokens/edge) |
| Session deduplication | Yes (84% across a session) | No |
| Delta encoding | Yes (81.2% savings on re-queries) | No |
| Distance grouping | Yes (## targets, ## related) | No |
| Graph-native (nodes + edges) | Yes (graph profile) | No |
| Generic data (any JSON) | Yes (generic profile) | Yes |
| Streaming encode | Yes (true zero-buffering, O(1) memory, [?] + trailer) | Output-side only (requires full value in memory) |
| Key folding (dotted paths) | No | Yes |
| LLM comprehension (generic, 500 orders) | 100% on every frontier model | 92.3% (fails on GPT-5.5, Gemini Flash) |
| LLM comprehension (graph, 500 symbols) | 91.2% avg (25 runs, 10 models) | 68.8% avg |
| LLM generation (output tokens) | 75% fewer than JSON | 40% fewer than JSON |
| Human-readable | Dense, agent-optimized | YAML-like, human-friendly |
| Zero dependencies | Yes | Yes |
| Language support | Go, TypeScript, Python, Rust, Swift, Kotlin | TypeScript, Go |
| MCP proxy (zero-code adoption) | Yes | Yes ("Tooner") |
Where GCF wins
1. Token efficiency across 16 real-world datasets
16 datasets representing actual LLM tool response payloads. Same tokenizer (o200k_base), spec-compliant encoders:
| Dataset | GCF | TOON | GCF vs TOON |
|---|---|---|---|
| Employee records (flat) | 49,061 | 49,966 | -1.8% |
| E-commerce orders (nested) | 50,343 | 73,246 | -31.3% |
| Analytics time-series | 8,404 | 9,127 | -7.9% |
| GitHub repositories | 8,599 | 8,744 | -1.7% |
| Event logs (semi-uniform) | 95,193 | 154,032 | -38.2% |
| Nested config | 617 | 618 | -0.2% |
| LSP symbol search | 5,442 | 5,365 | +1.4% |
| PR file changes | 2,623 | 2,657 | -1.3% |
| Distributed trace | 4,318 | 4,959 | -12.9% |
| Database query results | 17,716 | 17,969 | -1.4% |
| File tree + diagnostics | 6,018 | 6,894 | -12.7% |
| Multi-tool composite | 3,131 | 3,192 | -1.9% |
| Order history (shared schemas) | 13,295 | 16,454 | -19.2% |
| Blast radius response | 6,561 | 7,831 | -16.2% |
| Kubernetes pod status | 40,097 | 60,603 | -33.8% |
| Enterprise org hierarchy | 222,196 | 330,486 | -32.8% |
| TOTAL | 533,614 | 752,143 | -29.0% |
GCF wins 15/16. TOON's one win: LSP symbols (77 tokens, 1.4%, tokenizer artifact).
GCF's largest advantage is on semi-uniform and nested data (30-38% smaller) because GCF's inline schema optimization encodes nested objects positionally. TOON's tabular format requires all rows to have identical fields. When data is semi-uniform or has nested sub-objects, TOON falls back to its less efficient encoding.
Reproducible: blackwell-systems/toon-benchmark
2. Edge encoding (the structural advantage)
TOON has no concept of references between records. Every relationship must spell out the full identifier of both endpoints:
TOON edges (repeated identifiers):
edges[3]{source,target,type}:
github.com/org/repo/pkg.NewServer,github.com/org/repo/pkg.AuthMiddleware,calls
github.com/org/repo/pkg.AuthMiddleware,github.com/org/repo/pkg.ValidateToken,calls
github.com/org/repo/pkg.ValidateToken,github.com/org/repo/internal.TokenCache,referencesGCF edges (local IDs):
## edges [3]
@0<@3 calls
@1<@0 calls
@6<@1 referencesSame information. GCF: ~4 tokens per edge. TOON: ~30-100 tokens per edge depending on identifier length. This advantage grows with longer qualified names (common in Java/Go packages) and higher edge density (call graphs, dependency graphs).
This is a structural limitation of TOON. It cannot be fixed without adding a local-ID system, which would make it a different format.
3. Session deduplication (TOON can't do this)
In multi-turn LLM interactions, the same data appears across multiple tool responses. GCF tracks what's been sent and replaces known records with bare references:
Call 1: full declarations
GCF profile=graph tool=context_for_task symbols=15 edges=10 session=true
## targets
@0 fn pkg.AuthMiddleware 0.78 lsp_resolved
@1 fn pkg.ValidateToken 0.72 lsp_resolved
...Call 5: 92% bare references
GCF profile=graph tool=context_for_task symbols=22 edges=16 session=true
## targets
@0 # previously transmitted
@1 # previously transmitted
@2 # previously transmitted
@18 fn pkg.NewEndpoint 0.88 lsp_resolved
...| Call | New records | Bare refs | Savings vs JSON |
|---|---|---|---|
| 1 | 100% | 0% | 68% (base GCF) |
| 2 | 35% | 65% | 84% |
| 3 | 20% | 80% | 86% |
| 5 | 8% | 92% | 86% |
TOON retransmits every record every call; it has no session concept. By the 5th tool call, each GCF response has shrunk to mostly bare references (86% fewer tokens than JSON, up to 99% per call with delta), while every TOON response is still the full table.
This isn't a feature that can be bolted on. Session dedup requires the format to support bare references (@N # previously transmitted), which requires local IDs (@N), which TOON doesn't have.
4. Delta encoding (TOON can't do this)
When the LLM re-queries and the data changed slightly, GCF sends only the diff:
GCF profile=graph tool=context_for_task delta=true base_root=sha256:0123456789abcdef... new_root=sha256:fedcba9876543210... savings=81%
## removed
fn pkg.OldHandler
## added
@0 fn pkg.NewHandler 0.85 rwr 0
## edges_removed
pkg.Router -> pkg.OldHandler calls
## edges_added
pkg.Router -> pkg.NewHandler calls81.2% savings on re-queries in production. TOON must retransmit the entire payload even if one record changed.
Delta is not graph-only. The generic profile has the same mechanism (a keyed diff with ## added / ## changed / ## removed sections and content-addressed roots; SPEC Section 10a), so evolving tabular result sets get the same re-query savings. TOON has neither form.
5. Distance grouping (semantic structure)
GCF encodes how far each record is from the query center:
## targets ← direct matches (distance 0)
@0 fn pkg.Auth 0.92 lsp
## related ← one hop away (distance 1)
@3 fn pkg.Server 0.65 lsp
## extended ← broader context (distance 2)
@6 type pkg.Cache 0.41 structuralThe LLM immediately knows what's most relevant without scanning the entire payload. TOON encodes all records in a flat list with no semantic grouping.
LLM generation validity
28 generation runs across 9 models and 3 providers. Same data, same prompt structure, output validated through real decoders (including TOON's official toon-go library).
| Model | GCF | TOON | JSON |
|---|---|---|---|
| Claude Opus 4.6 | 5/5 | 0/5 | 5/5 |
| Claude Sonnet 4.6 | 5/5 | 2-3/5 | 5/5 |
| GPT-5.5 | 4-5/5 | 1-2/5 | 5/5 |
| GPT-5.4 | 5/5 | 0/5 | 5/5 |
| Gemini 2.5 Pro | 5/5 | 1/5 | 5/5 |
| Gemini 3.1 Pro | 5/5 | 0/5 | 5/5 |
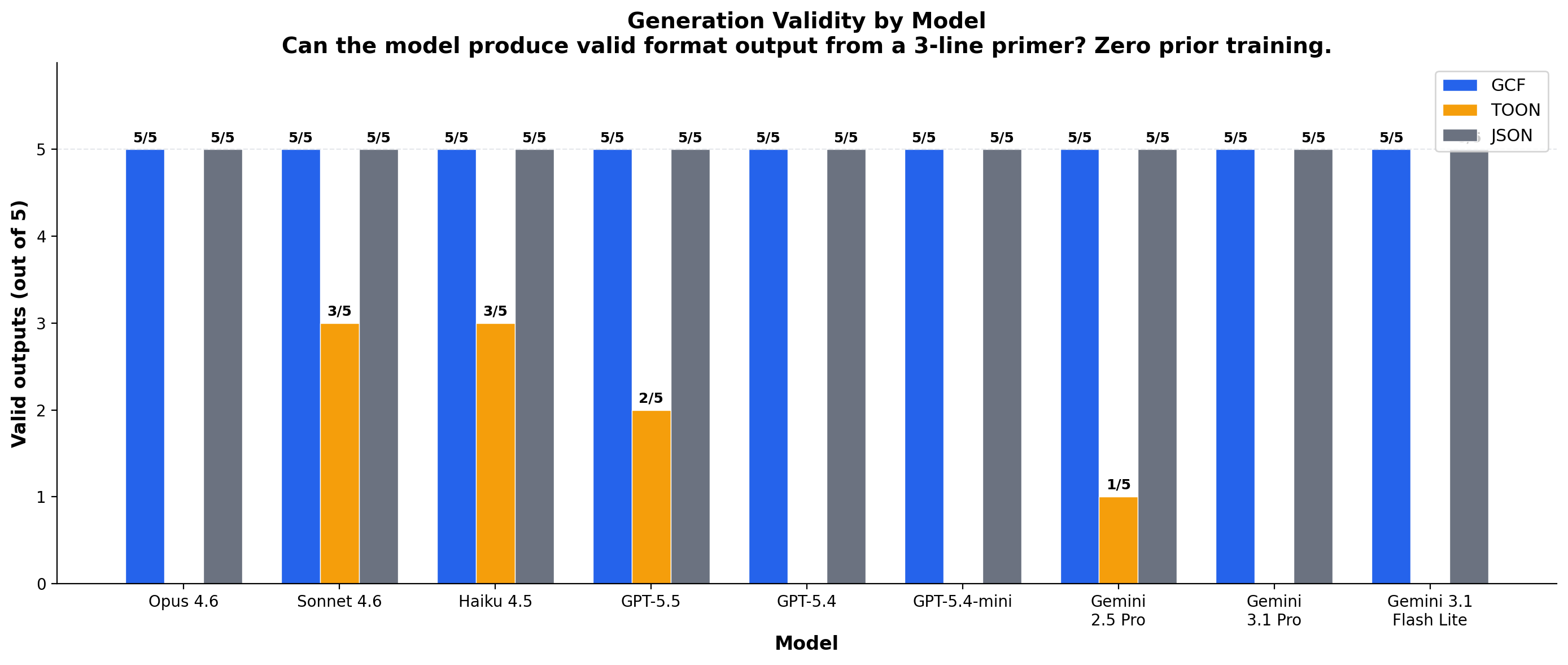
TOON's official decoder rejects the output on 7 of 9 models. The failure is structural: TOON's flat columns require the model to encode semantic categories as integers. When told "this symbol is a target," the model writes target in the distance column. TOON's decoder expects 0. Every model fails to perform this mapping unprompted.
GCF expresses distance through section placement (## targets, ## related). No integer mapping required. The format aligns with how LLMs naturally express grouped data.

When TOON is given pre-encoded integers (hand-holding the model through the mapping), performance improves on some models but is still inconsistent. Even in the best case, TOON output is 28% larger than GCF.
GCF output is 63% smaller than JSON and 33% smaller than TOON at 100 symbols. See the full generation data for all runs.
TOON's comprehension benchmarks don't test at scale
TOON's retrieval accuracy benchmark uses datasets of 100 rows or fewer and reports a 1.4 percentage point accuracy improvement over JSON (76.4% vs 75.0%). At this scale, all formats perform similarly because JSON's structural noise hasn't yet overwhelmed the model's attention.
GCF's comprehension eval tests at two scales:
Generic profile (500 orders, nested data, 7 models):
| Format | Frontier models (6) | Weak models (1) |
|---|---|---|
| GCF | 100% | 69.2% |
| TOON | 92.3-100% | 69.2% |
| JSON | 76.9-100% | 61.5% |
GCF: 100% on every frontier model. TOON fails on GPT-5.5 (count_premium_customers). JSON fails on Gemini 2.5 Flash (3 questions wrong).
Graph profile (500 symbols + 200 edges, 10 models, 25 runs):
| Format | Avg accuracy | Tokens |
|---|---|---|
| GCF | 91.2% | 11,090 |
| TOON | 68.8% | 16,378 |
| JSON | 54.1% | 53,341 |
25 runs. GCF wins 24, ties 1, loses 0. The difference between formats is invisible at 100 rows and undeniable at 500.
Scale test (1000 orders): JSON doesn't fit in 200K context. TOON doesn't fit on Sonnet. GCF (47K tokens) is the only format that works.
TOON publishes zero multi-model comprehension data and zero generation validity data.
"But GCF isn't human-readable"
Neither is protobuf. Neither are HTTP headers. Readability is a last-mile rendering concern, not a wire format property.
The agent reads GCF (cheap, 50-69% fewer tokens than JSON in the context window), does its work, then calls decode() at the end if a human needs to see the result. The context window savings are already banked. The decode costs one function call.
TOON optimizes for the case where a human is scanning the raw wire format. GCF optimizes for the case where an agent is consuming it and a human can view the decoded output if they need to. The second case is the common case. The first case is debugging.
Where TOON wins
One case out of 16 datasets:
- LSP symbol search (+77 tokens, 1.4%): A flat tabular array where TOON's comma delimiter tokenizes slightly better than GCF's pipe delimiter. GCF is fewer bytes but more tokens due to how the tokenizer splits on
|vs,.
77 tokens. GCF saves 218,606 tokens across the other 15 datasets.
TOON's encodeLines() is output-side streaming only (the full value must be in memory before encoding starts). GCF's StreamEncoder is true input-side streaming with zero buffering and O(1) memory per row. See the streaming guide for the full comparison.
The bottom line
Tokenization: TOON's tab delimiter is worse than JSON's quote
We ran the same tokenizer analysis on TOON's grammar symbols across 43 tokenizers from 20 providers. TOON uses tab characters as column delimiters. Tabs merge with adjacent content far more aggressively than JSON's quotes:
| Format | Delimiter merge rate | Checks |
|---|---|---|
| TOON (tab) | 32.91% | 283/860 |
| JSON (quote) | 8.17% | 158/1,935 |
| GCF (pipe) | 0.47% | 135/29,025 |
GPT-4o has a 100% tab merge rate: every single word tested merges with the preceding tab. GPT-4 cl100k merges 95%. These are the two most widely deployed tokenizers in the world. GPT-4's vocabulary has 1,173 tab+letter entries and GPT-4o has 1,036. Tab-separated data was so common in training corpora that the tokenizer absorbed tabs into adjacent words far more aggressively than any other delimiter.
TOON's indentation also tokenizes inconsistently across models: the same 4-space indent produces 4 different tokenizations across tokenizers. The model sees different nesting depth depending on which tokenizer processes it.
An exhaustive vocabulary scan of all 43 tokenizers found 1,238 unique words that can merge with TOON's tab across any vocabulary. JSON's three structural characters have a combined surface of 707 words (quote 193, colon 232, comma 282). GCF's pipe has 24 (52x smaller than tab, 29x smaller than JSON combined). The tab has the largest merge surface of any common delimiter character. The pipe has the smallest.
This matters for comprehension at scale: Ildiz et al. proved that self-attention weights tokens proportionally to their frequency in the sequence. When TOON's merged tab-field tokens dominate the sequence, the attention budget is mathematically dominated by structural noise. See the full tokenizer analysis for how this compounds at 500+ rows.
GCF does everything TOON does, plus five things TOON structurally cannot add without becoming a different format:
- Local IDs and edge encoding (requires
@Nreferences) - Session deduplication (requires bare references, which require local IDs)
- Delta encoding (requires content-addressed identity)
- Distance grouping (requires semantic section headers)
- True streaming encode (requires deferred counts + trailer; TOON spec mandates upfront
[N])
On 16 real-world datasets, GCF wins 15. Overall: 29% fewer tokens.
The gap widens over time. First call: GCF saves 34% vs TOON. From there it compounds: TOON re-sends the entire payload on every call, while GCF's session responses shrink toward bare references, so the advantage grows every turn. No format change can close that gap without adding session state, which requires local IDs, which requires a fundamental redesign.
One decision, measured six ways
TOON's disadvantages are not a list of unrelated shortcomings. They are the downstream consequences of a single design decision: replacing JSON's explicit delimiters with implicit, whitespace/tab-based structure in a flat tabular layout. That one choice surfaces independently across every axis we measure.
| Axis | Consequence of implicit delimiters | Measured |
|---|---|---|
| Tokenization | tab merges with adjacent content, dissolving boundaries into single tokens | 32.91% merge rate, 1,238 mergeable words (worst of any common separator; GCF pipe: 0.47%) |
| Comprehension | the model cannot filter a flat 500-row table by column value | 68.8% vs GCF 91.2% across 25 runs |
| Generation | flat columns encode categories as integers; models write labels and the decoder rejects | TOON's own decoder rejects LLM output on 7 of 9 models |
| Token efficiency | flat rows repeat structure; edges carry no local IDs | GCF wins 15 of 16 datasets, 29% fewer tokens overall |
| Security | no explicit boundary between untrusted content and schema | "Delimiter Dissolution": 90% injection leak on Qwen (JSON 0%) |
| Multi-turn | parsing ambiguity compounds across turns | independent cascade finding (Kutschka et al., arXiv 2605.29676) |
Explicit delimiters are not a stylistic preference. They are the boundary the tokenizer needs to keep structure and content in separate tokens, the boundary the model needs to filter columns, the boundary a generator needs to emit valid output, and the boundary that separates trusted schema from untrusted input. TOON removed it once. The cost recurs everywhere.
The security row is the newest of these. A controlled four-arm study (JSON, TOON, S-TOON, GCF) across five models confirms TOON's delimiter-injection vulnerability where it appears, shows Alshaer's proposed S-TOON middleware actively increases leakage, and finds GCF is the only format whose leak rate never exceeds the JSON control. See the structural-injection study.
TOON Is Not Lossless
TOON claims "deterministic, lossless round-trips" on their landing page. We tested it.
10 million random structured values encoded with @toon-format/toon (their official npm package), decoded back, and compared to the original.
| GCF | TOON | |
|---|---|---|
| Round-trips tested | 43,000,000,000+ | 10,000,000 |
| Success rate | 100% | 92.46% |
| Decode errors | 0 | 577,717 |
| Silent data corruption | 0 | 176,487 |
| Total failures | 0 | 754,204 |
7.54% of TOON round-trips fail. 176,487 of those are silent: the encode and decode both "succeed" but the output doesn't match the input. The data is quietly corrupted with no error.
What breaks TOON
TOON's encoder does not quote strings containing structural characters ([, ], {, }, :). The decoder then misparses those strings as format syntax.
Example (seed 132): the string "name[3]: a,b,c" is encoded as a bare value. The decoder sees name[3]: and interprets it as an inline array declaration, returning ["a","b","c"] instead of the original string. Silent corruption.
Example (seed 2780): the string "1x#[3tyevb6L][_:qE" causes a decode error because the decoder tries to parse [_ as an array bracket.
The test
The fuzz test generates random JSON values (objects, arrays, scalars, nested to depth 3-4) using a seeded PRNG. Values include strings with commas, brackets, braces, colons, newlines, tabs, unicode, and other characters that probe format boundary handling. Every test is deterministic and reproducible from its seed.
# Reproduce
git clone https://github.com/blackwell-systems/gcf
cd gcf/eval
npm install @toon-format/toon
node toon-fuzz.mjs 10000000Full log: toon-fuzz-10M-2026-06-16.log
Why GCF doesn't have this problem
GCF's scalar grammar quotes any string that contains pipe (|), newline, or could be misinterpreted as a typed literal. The quoting rules are specified in the grammar and enforced by all 6 implementations. 43 billion round-trips across 5 formats with zero mismatches is the proof.
Try both formats in the playground with your own data.
Get started in 5 minutes with any of 6 languages.