Benchmarks (Full Data)
Every number on the benchmarks page comes from the runs below. This page has the complete per-run data, failure analysis, and generation results across 11 models and 4 providers. All raw logs are in the eval/results directory.
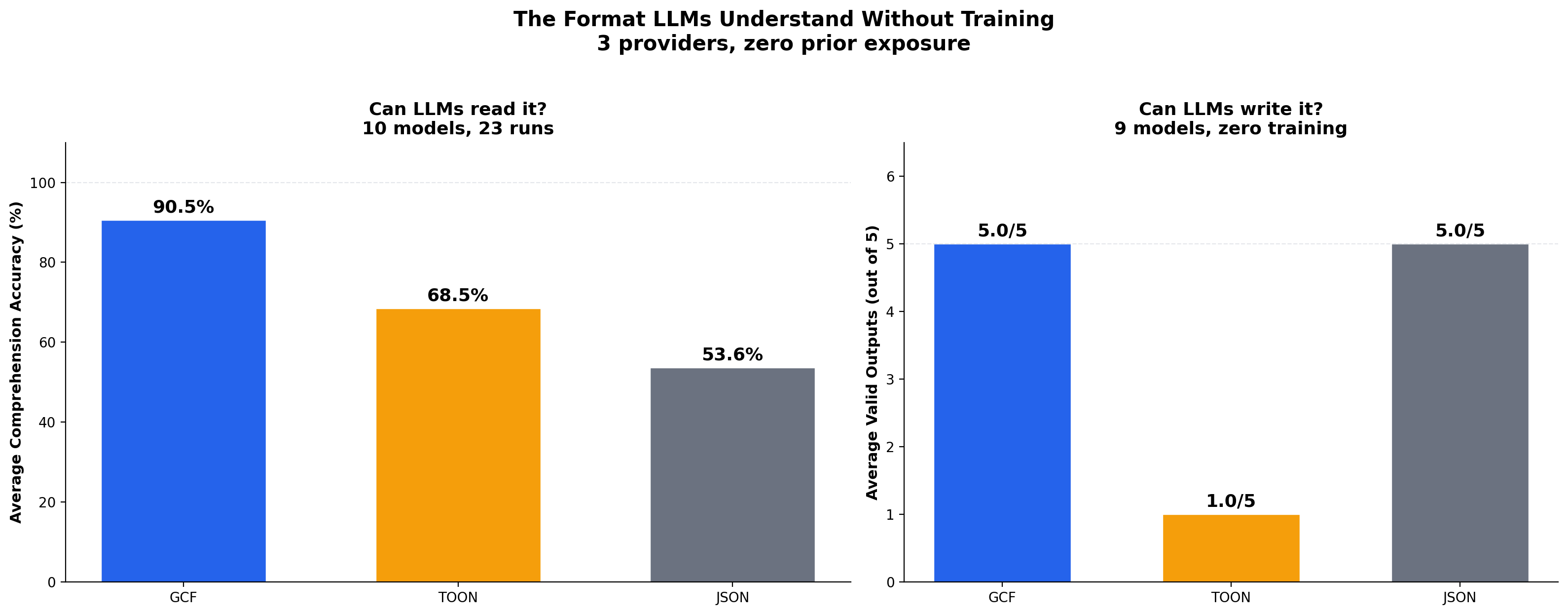
Generic Profile: All Runs
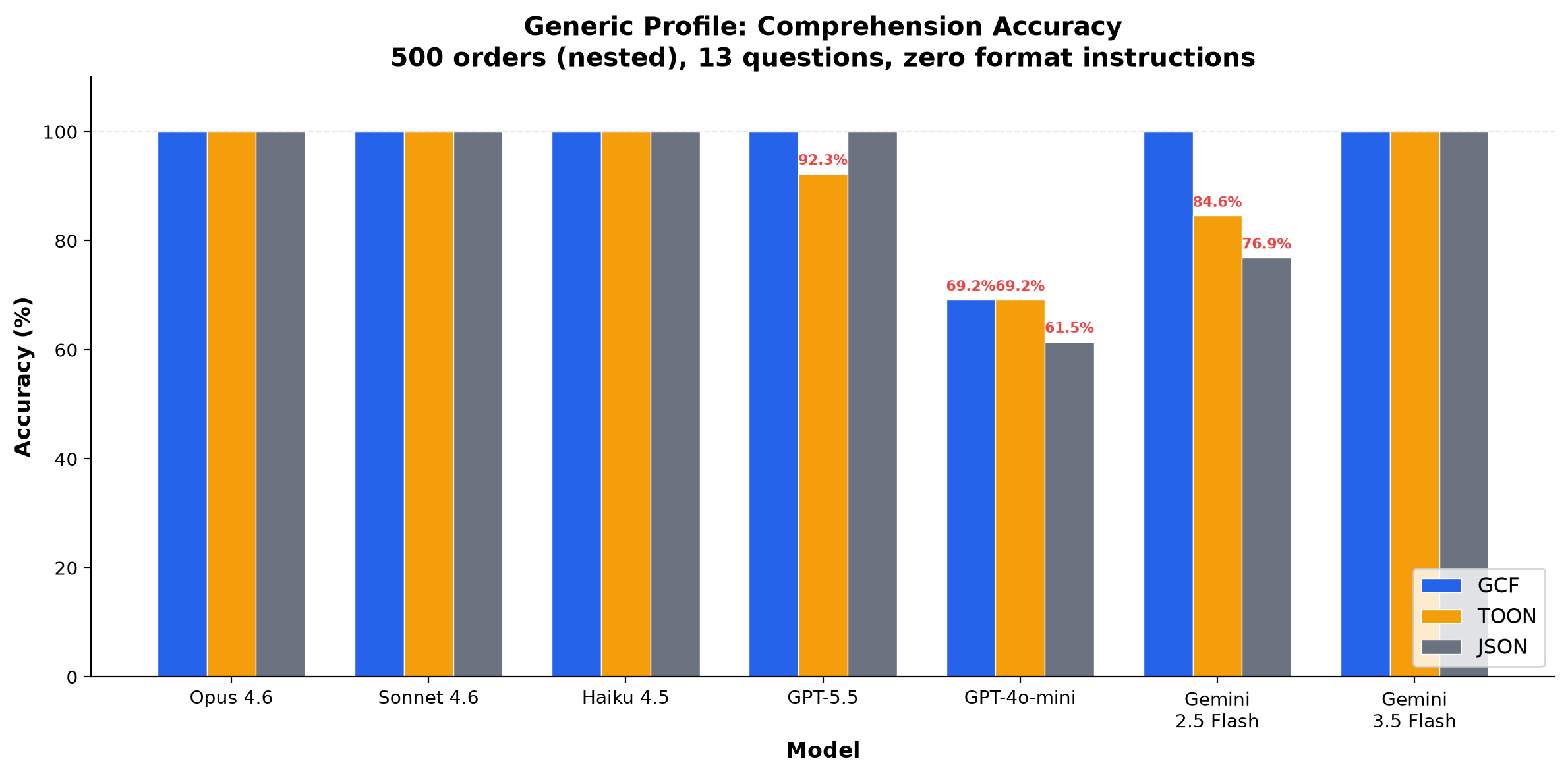
500 orders with nested customer objects and line items. 13 structured extraction questions. Zero format instructions. Deterministic answers, no LLM judge.
| Model | Provider | Run | Orders | GCF | JSON | TOON | Notes |
|---|---|---|---|---|---|---|---|
| Claude Opus 4.6 | Anthropic | 1 | 500 | 100% | 100% | 100% | All exact |
| Claude Opus 4.6 | Anthropic | 2 | 500 | 100% | 100% | 100% | All exact |
| Claude Sonnet 4.6 | Anthropic | 1 | 500 | 100% | 100% | 100% | All exact |
| Claude Sonnet 4.6 | Anthropic | 2 | 500 | 100% | 100% | 100% | All exact |
| Claude Sonnet 4.6 | Anthropic | 3 | 500 | 100% | 100% | 92.3% | TOON: count_premium_customers off |
| Claude Haiku 4.5 | Anthropic | 1 | 500 | 100% | 100% | 100% | All exact |
| Claude Haiku 4.5 | Anthropic | 2 | 500 | 100% | 100% | 100% | All exact |
| Claude Haiku 4.5 | Anthropic | 3 | 500 | 100% | 100% | 100% | All exact |
| Claude Haiku 4.5 | Anthropic | 4 | 500 | 100% | 100% | 100% | All exact |
| GPT-5.5 | OpenAI | 1 | 500 | 100% | 100% | 100% | All exact |
| GPT-5.5 | OpenAI | 2 | 500 | 100% | 100% | 92.3% | TOON failed count_premium_customers |
| GPT-4o-mini | OpenAI | 1 | 500 | 69.2% | 61.5% | 69.2% | Weak model, all formats struggle |
| Gemini 2.5 Pro | 1 | 500 | 100% | 100% | 100% | All exact | |
| Gemini 2.5 Pro | 2 | 500 | 100% | 100% | 100% | All exact | |
| Gemini 2.5 Pro | 3 | 500 | 100% | 100% | 100% | All exact | |
| Gemini 3.1 Pro Preview | 1 | 500 | 100% | 100% | 100% | All exact | |
| Gemini 3.5 Flash | 1 | 500 | 100% | 100% | 100% | All exact | |
| Gemini 3.5 Flash | 2 | 500 | 100% | 100% | 100% | All exact | |
| Gemini 2.5 Flash | 1 | 500 | 100% | 76.9% | 84.6% | JSON/TOON failed counting questions | |
| Gemini 2.5 Flash | 2 | 500 | 90.0% | 75.0% | 81.8% | All formats degraded | |
| Gemini 2.5 Flash | 3 | 500 | 90.0% | 75.0% | 81.8% | All formats degraded | |
| Gemini 2.5 Flash | 4 | 500 | 100% | 69.2% | 92.3% | GCF perfect, JSON 69.2% | |
| Mistral Medium 3.5 | Mistral | 1 | 500 | 84.6% | 84.6% | 76.9% | GCF ties JSON, beats TOON |
| Mistral Medium 3.5 | Mistral | 2 | 500 | 76.9% | 91.7% | 76.9% | JSON wins (outlier) |
| Mistral Medium 3.5 | Mistral | 3 | 500 | 84.6% | 76.9% | 76.9% | GCF wins |
| Mistral Medium 3.5 | Mistral | 4 | 500 | 84.6% | 75.0% | 76.9% | GCF wins |
| Mistral Large 3 | Mistral | 1 | 500 | 69.2% | 69.2% | 69.2% | All tied, model is bottleneck |
27 runs, 11 models, 4 providers. Frontier models (Opus, Sonnet, Haiku, GPT-5.5, Gemini 2.5 Pro, Gemini 3.1 Pro, Gemini 3.5 Flash) achieve 100% GCF on every run. GCF averages equal or better than JSON across runs on every model. TOON is consistently the weakest format.
Scale Test: 1000 Orders
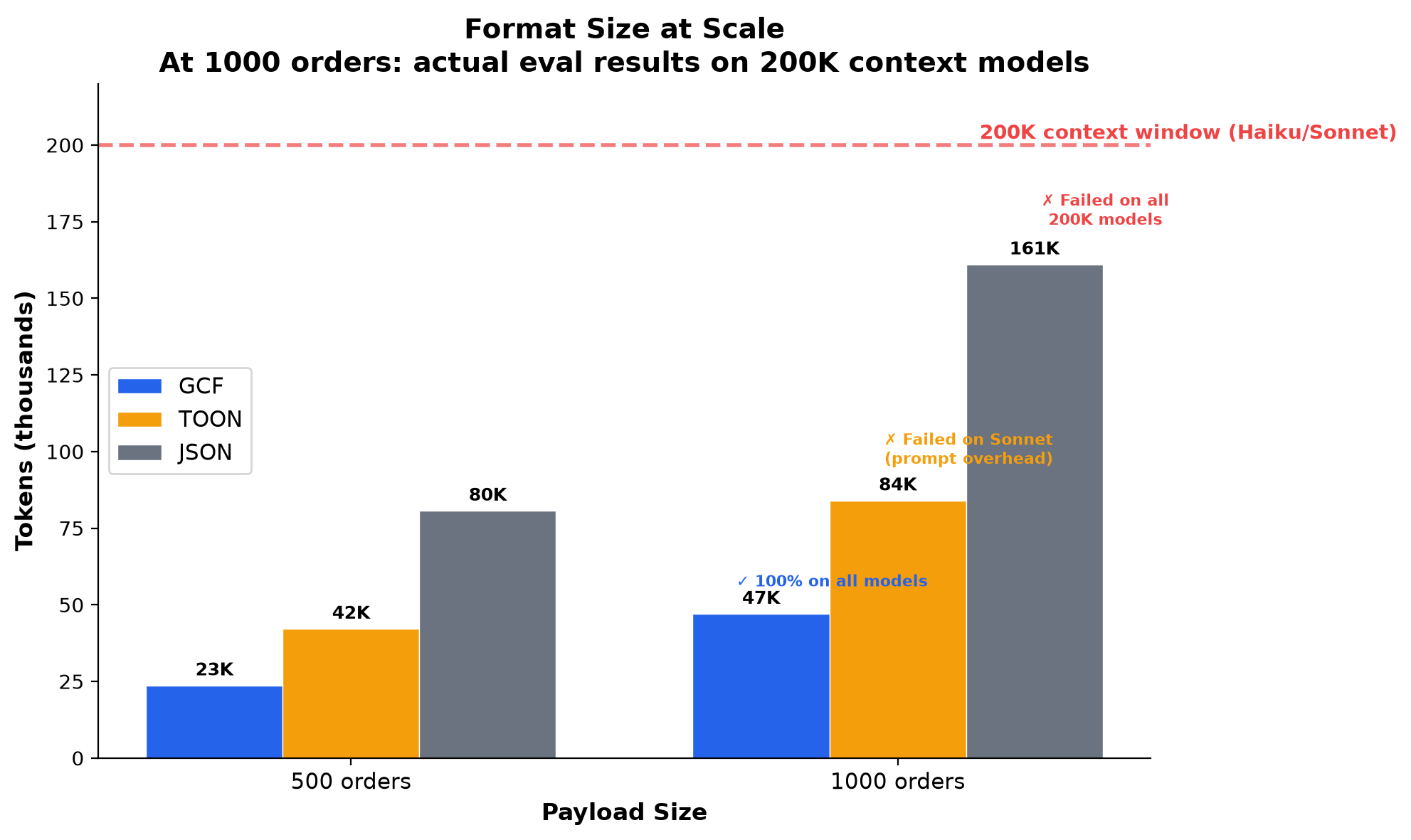
| Model | Context | GCF (47K) | TOON (84K) | JSON (161K) |
|---|---|---|---|---|
| Claude Haiku 4.5 | 200K | 100% (13/13) | 100% (13/13) | IMPOSSIBLE |
| Claude Sonnet 4.6 | 200K | 92.3% (12/13) | IMPOSSIBLE | IMPOSSIBLE |
| Claude Opus 4.6 (run 1) | 1M | 100% (13/13) | 100% (13/13) | 100% (13/13) |
| Claude Opus 4.6 (run 2) | 1M | 100% (13/13) | 100% (13/13) | 100% (13/13) |
| GPT-5.5 | - | 100% (6/6) | 100% (5/5) | 100% (6/6) |
At 1000 orders, JSON (161K tokens) exceeds 200K context. TOON (84K) also exceeds effective context on Sonnet. GCF (47K) is the only format that reliably fits on 200K context models.
Generic Profile Failures (frontier models only)
GCF has zero failures across all generic profile runs on Anthropic and Google frontier models (Opus, Sonnet, Haiku, GPT-5.5, Gemini 2.5 Pro, Gemini 3.1 Pro, Gemini 3.5 Flash). The only frontier-model failure on any format:
| Model | Format | Question | Expected | Got |
|---|---|---|---|---|
| GPT-5.5 | TOON | count_premium_customers | 200 | 250 |
| Sonnet 4.6 | TOON | count_premium_customers | 200 | 125 |
On mid-tier models (Gemini 2.5 Flash, Mistral Medium), all formats show occasional precision errors on counting and aggregation questions at 500 records. GCF averages equal or better than JSON across runs on every model.
Token Efficiency: 15 Datasets
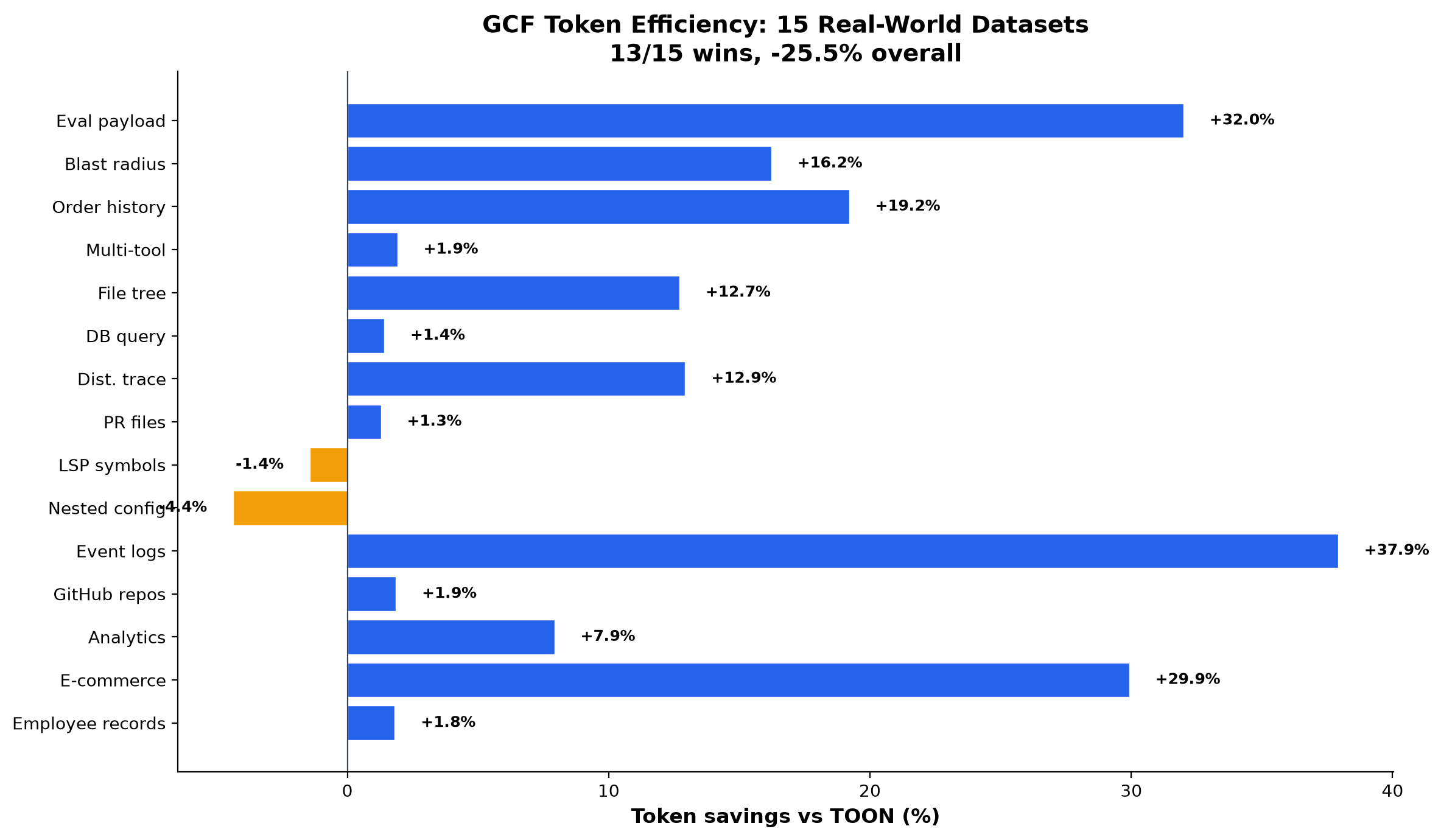
16 real-world datasets. GCF wins 15/16 vs TOON, -29% overall, -56% vs JSON.
Dataset 15 is the exact payload used in the comprehension eval above. The format that achieves 100% accuracy uses 32% fewer tokens than TOON and 57.5% fewer than JSON.
Graph Profile: All Runs
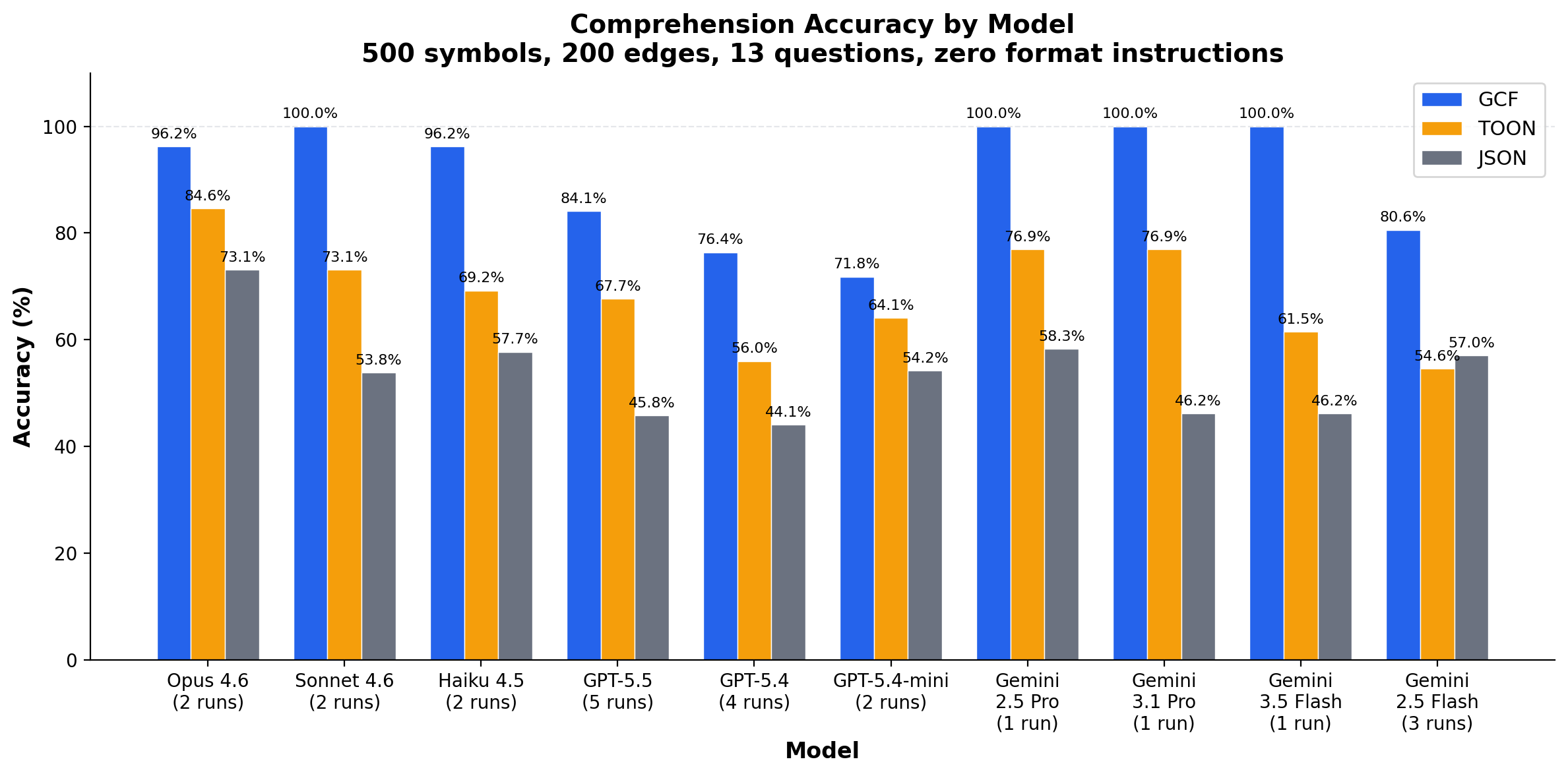
500 symbols, 200 edges, 13 structured extraction questions, zero format instructions. Each run generates a fresh random payload with different symbol names and edge distributions, so variance across runs reflects the model's actual comprehension rather than memorization of a fixed dataset.
| Model | Run | GCF | TOON | JSON | GCF wins? |
|---|---|---|---|---|---|
| Claude Opus 4.6 | 1 | 100% | 92.3% | 76.9% | ✓ |
| Claude Opus 4.6 | 2 | 92.3% | 76.9% | 69.2% | ✓ |
| Claude Sonnet 4.6 | 1 | 100% | 76.9% | 53.8% | ✓ |
| Claude Sonnet 4.6 | 2 | 100% | 69.2% | 53.8% | ✓ |
| Claude Haiku 4.5 | 1 | 92.3% | 69.2% | 61.5% | ✓ |
| Claude Haiku 4.5 | 2 | 100% | 69.2% | 53.8% | ✓ |
| GPT-5.5 | 1 | 91.7% | 66.7% | 50.0% | ✓ |
| GPT-5.5 | 2 | 76.9% | 69.2% | 46.2% | ✓ |
| GPT-5.5 | 3 | 76.9% | 69.2% | 46.2% | ✓ |
| GPT-5.5 | 4 | 91.7% | 66.7% | 50.0% | ✓ |
| GPT-5.5 | 5 | 83.3% | 66.7% | 36.4% | ✓ |
| GPT-5.4 | 1 | 75.0% | 58.3% | 41.7% | ✓ |
| GPT-5.4 | 2 | 76.9% | 53.8% | 46.2% | ✓ |
| GPT-5.4 | 3 | 76.9% | 53.8% | 38.5% | ✓ |
| GPT-5.4 | 4 | 83.3% | 58.3% | 50.0% | ✓ |
| GPT-5.4-mini | 1 | 76.9% | 61.5% | 58.3% | ✓ |
| GPT-5.4-mini | 2 | 66.7% | 66.7% | 50.0% | tied |
| Gemini 2.5 Flash | 1 | 76.9% | 58.3% | 53.8% | ✓ |
| Gemini 2.5 Flash | 2 | 75.0% | 50.0% | 57.1% | ✓ |
| Gemini 2.5 Flash | 3 | 90.0% | 55.6% | 60.0% | ✓ |
| Gemini 3.5 Flash | 1 | 100% | 61.5% | 46.2% | ✓ |
| Gemini 2.5 Pro | 1 | 100% | 76.9% | 58.3% | ✓ |
| Gemini 2.5 Pro | 2 | 100% | 80.0% | 72.7% | ✓ |
| Gemini 3.1 Pro | 1 | 100% | 76.9% | 46.2% | ✓ |
| Gemini 2.5 Flash | 4 | 100% | 46.2% | 46.2% | ✓ |
25 runs, 10 models, 3 providers. GCF wins 24, ties 1, loses 0. Four models achieve 100%: Sonnet, Gemini 2.5 Pro, Gemini 3.1 Pro, Gemini 3.5 Flash.
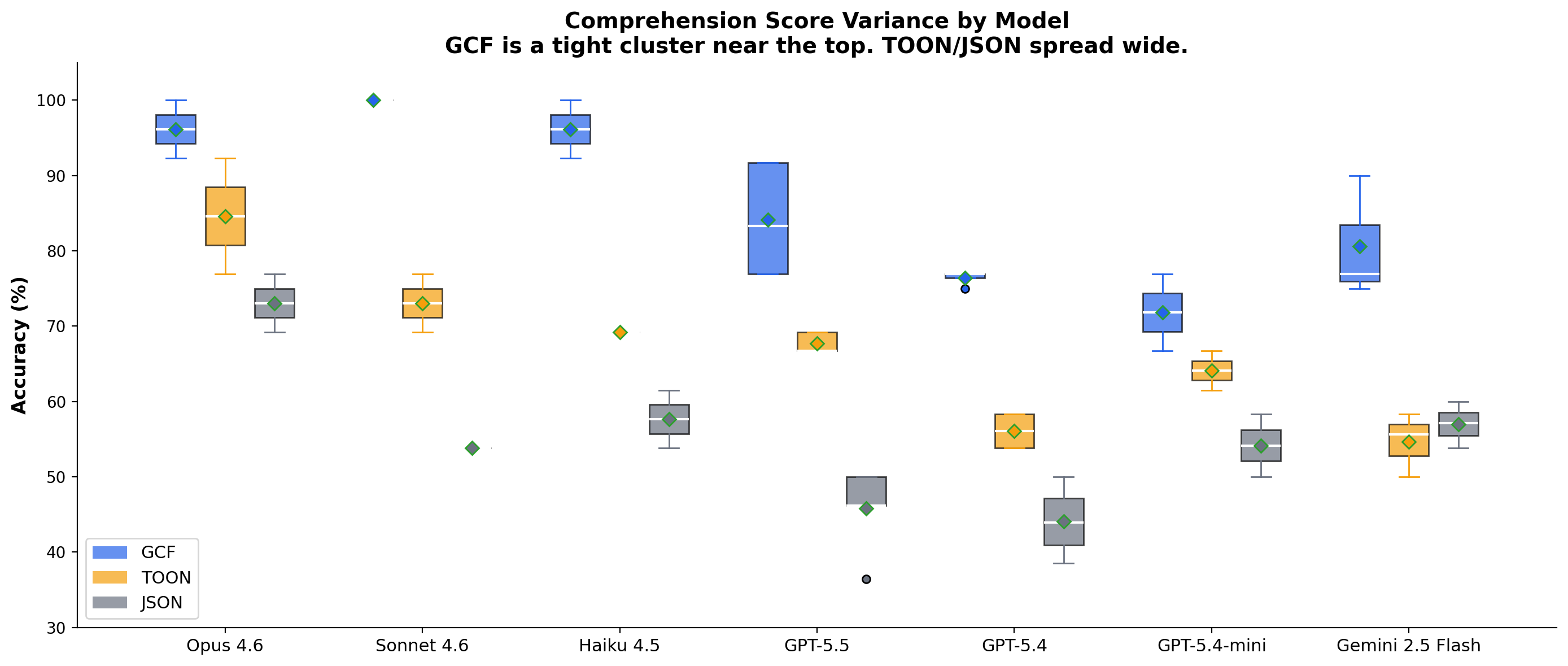
Score variance
GCF scores cluster tightly across runs. TOON and JSON scatter widely, especially on weaker models. This matters for production use: a format that scores 70% on one run and 40% on the next is unreliable regardless of its average.
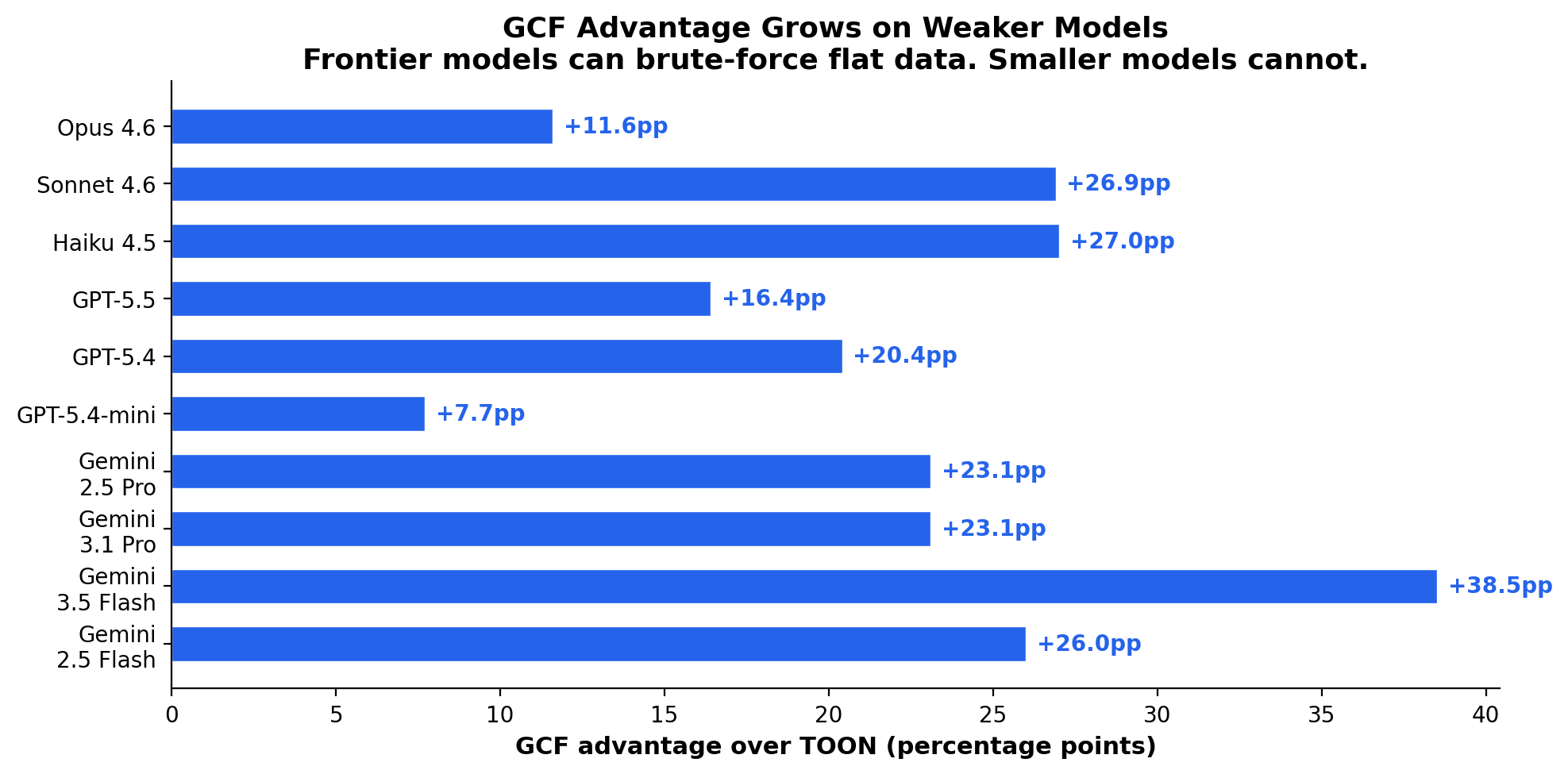
GCF advantage by model tier
GCF's margin over TOON and JSON grows as model capability decreases. Frontier models (Opus, Gemini Pro) can partially brute-force flat data through sheer capacity. Smaller models (GPT-5.4-mini, Gemini 2.5 Flash) cannot, and the gap widens to 20-30 percentage points. If you're optimizing for cost by using smaller models, format choice matters more, not less.
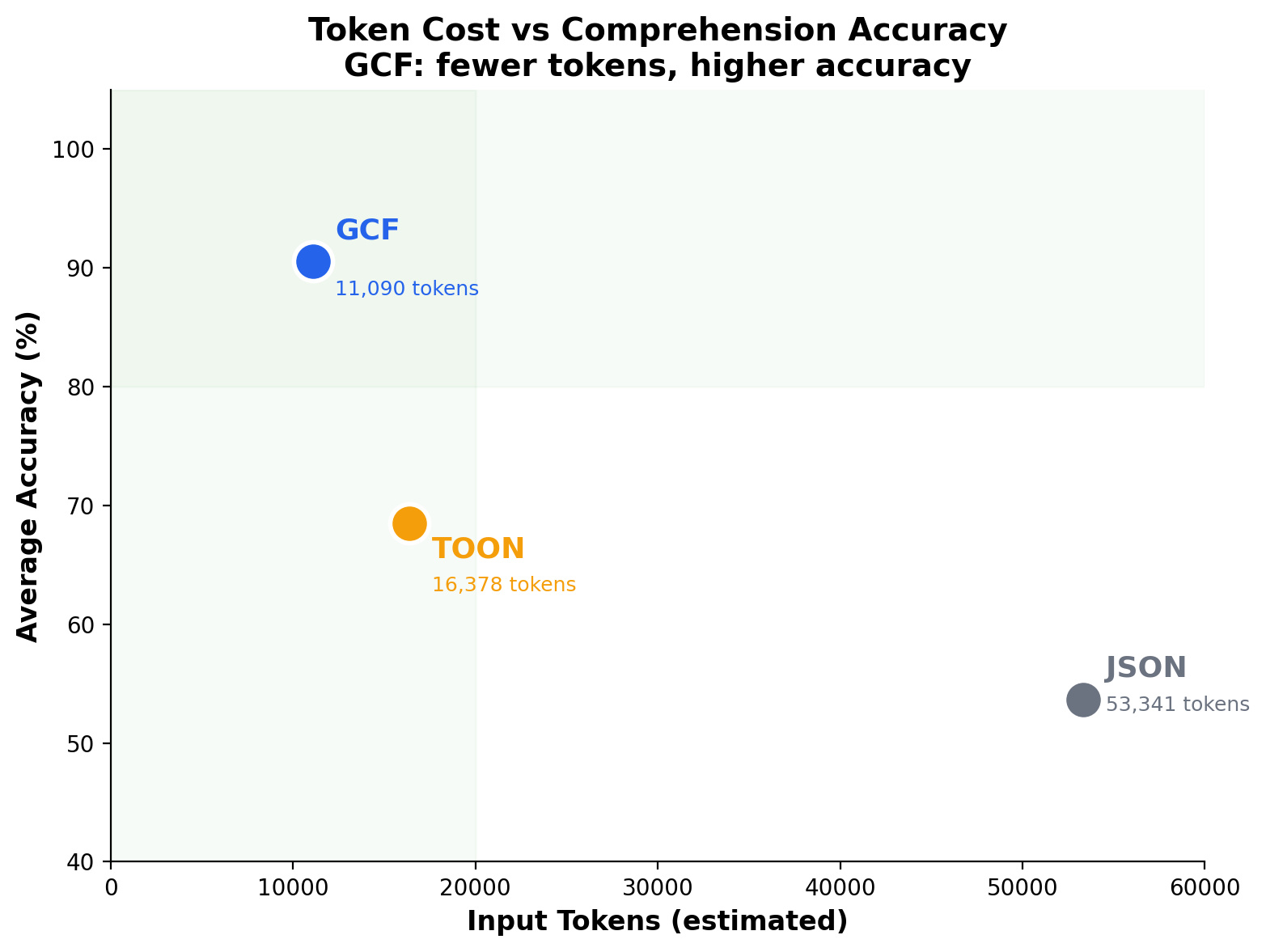
Token cost vs accuracy
GCF occupies the top-left quadrant: fewest tokens, highest accuracy. JSON occupies the bottom-right: most tokens, lowest accuracy. You usually trade cost for quality. GCF breaks that tradeoff.
Failure Taxonomy
Every wrong answer across all the graph runs was classified by failure type. The pattern is consistent: GCF fails differently than TOON and JSON. GCF errors are small (off by 1-2) because the model understood the structure but misread a number. TOON and JSON errors are large (off by 50-140) because the model couldn't extract the answer at all and guessed.
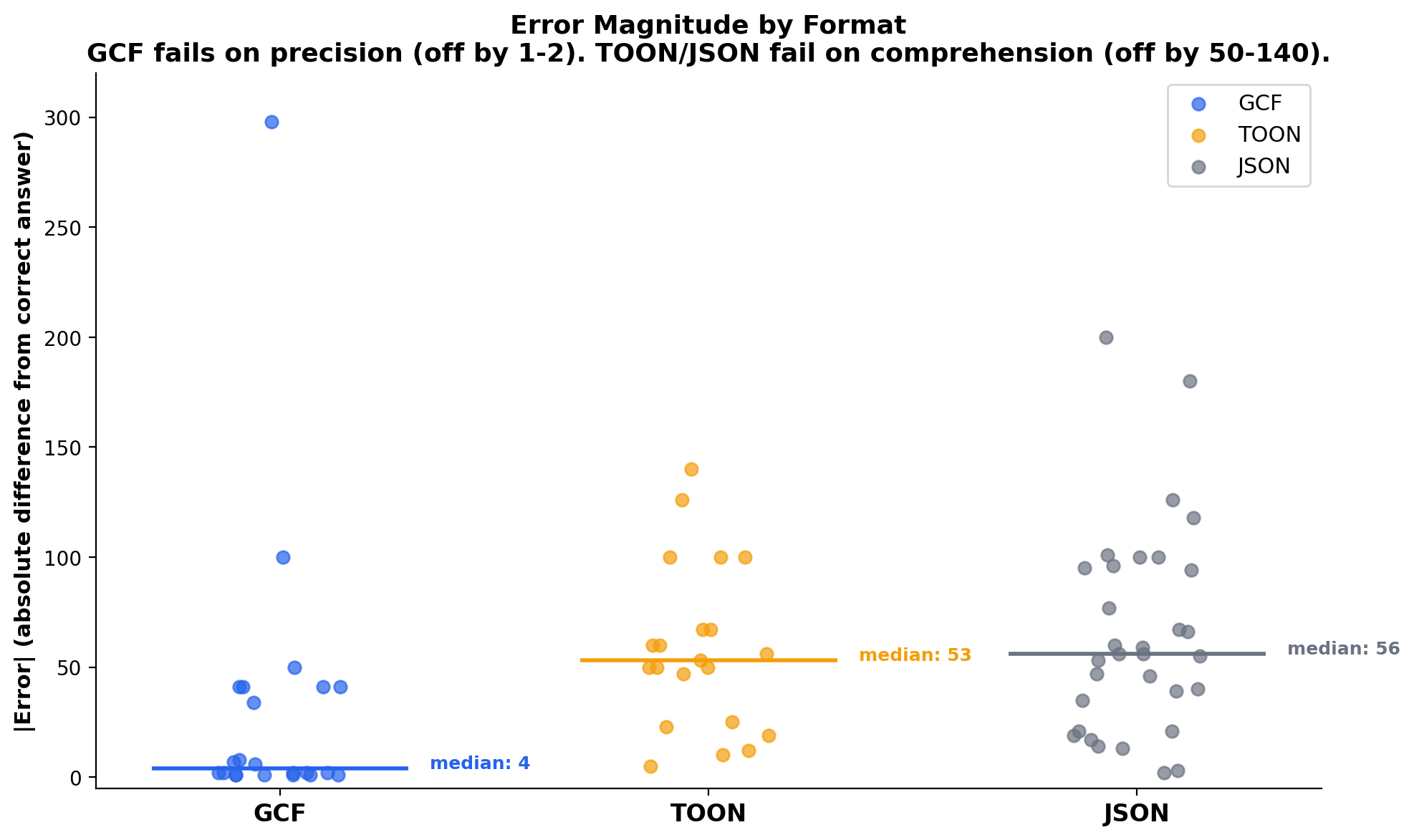
GCF median error: 4. TOON median error: 53. JSON median error: 56. GCF encodes answers structurally (## related [167]). TOON/JSON force the model to compute them from raw data. The difference between "slightly misread a header" and "couldn't comprehend the data" is the difference between a useful agent and a broken one.
GCF failures: precision errors
GCF fails on precision (off by 1-7). The structure is understood; the count is slightly misread. 36 total failures across the graph runs.
| Type | Count | Models | Cause |
|---|---|---|---|
| Off-by-1-2 header misread | 8 | Haiku (1), GPT-5.4 (3), mini (1), Gemini (3) | Header says [167], model reads 166. Tokenization artifact. |
| Column scan miscount | 11 | GPT-5.4 (5), mini (1), Gemini (5) | Must scan fn kind across rows. function_count=84 deterministically on GPT-5.4. |
| Field confusion | 2 | GPT-5.4 (1), mini (1) | Read symbol count instead of edge count. |
| Miscellaneous miscount | 5 | GPT-5.4 (2), Gemini (3) | edge_count, calls_edge_count off by larger margins. |
| Empty response | 10 | GPT-5.5 (10) | Context overwhelm at 53k+ input tokens. |
TOON failures: comprehension errors
TOON fails on comprehension (wrong by 50-140). The model cannot filter a flat list by column value at scale. 94 total failures across the graph runs.
| Type | Count | Models | Cause |
|---|---|---|---|
| Distance grouping failure | 45 | Opus/Sonnet (3), Haiku (6), GPT-5.4 (11), mini (5), Gemini (20) | Must scan 500 rows and filter by distance column. Wildly inconsistent answers. |
| Column scan miscount | 10 | Haiku (1), GPT-5.4 (4), mini (4), Gemini (1) | function_count wrong. Must scan all 500 rows by kind. |
| Attention decay (last row) | 7 | Opus/Sonnet (1), Haiku (3), GPT-5.4 (3) | last_symbol_kind wrong. Loses track at row 500. |
| Calls edge miscount | 10 | Opus/Sonnet (1), GPT-5.4 (4), mini (2), Gemini (3) | calls_edge_count wrong. Must scan edges and filter by type. |
| Symbol count wrong | 2 | Gemini (2) | Undercounts total symbols (250, 400 vs 500). |
| Empty response | 20 | GPT-5.5 (20) | Context overwhelm. Same as JSON. |
JSON failures: structural overwhelm
JSON fails on structure (empty responses, massive undercounts, chain-of-thought enumeration). The format itself prevents comprehension at scale. 131 total failures across the graph runs.
| Type | Count | Models | Cause |
|---|---|---|---|
| Empty string response | 33 | GPT-5.5 (33) | 53k tokens of repeated {"qualifiedName":...} overwhelms attention. |
| Massive undercount | 14 | Opus/Sonnet (2), Haiku (2), GPT-5.4 (4), mini (1), Gemini (5) | Field-name repetition dilutes signal. |
| Distance filter failure | 44 | Opus/Sonnet (7), Haiku (6), GPT-5.4 (11), mini (5), Gemini (15) | Must parse JSON objects AND filter by field value. |
| Column scan miscount | 37 | Opus/Sonnet (4), Haiku (3), GPT-5.4 (8), mini (4), Gemini (18) | edge_count, function_count, calls_edge_count wrong. |
| Attention decay (last row) | 3 | GPT-5.4 (2), Gemini (1) | last_symbol_kind reads edge type instead of kind. |
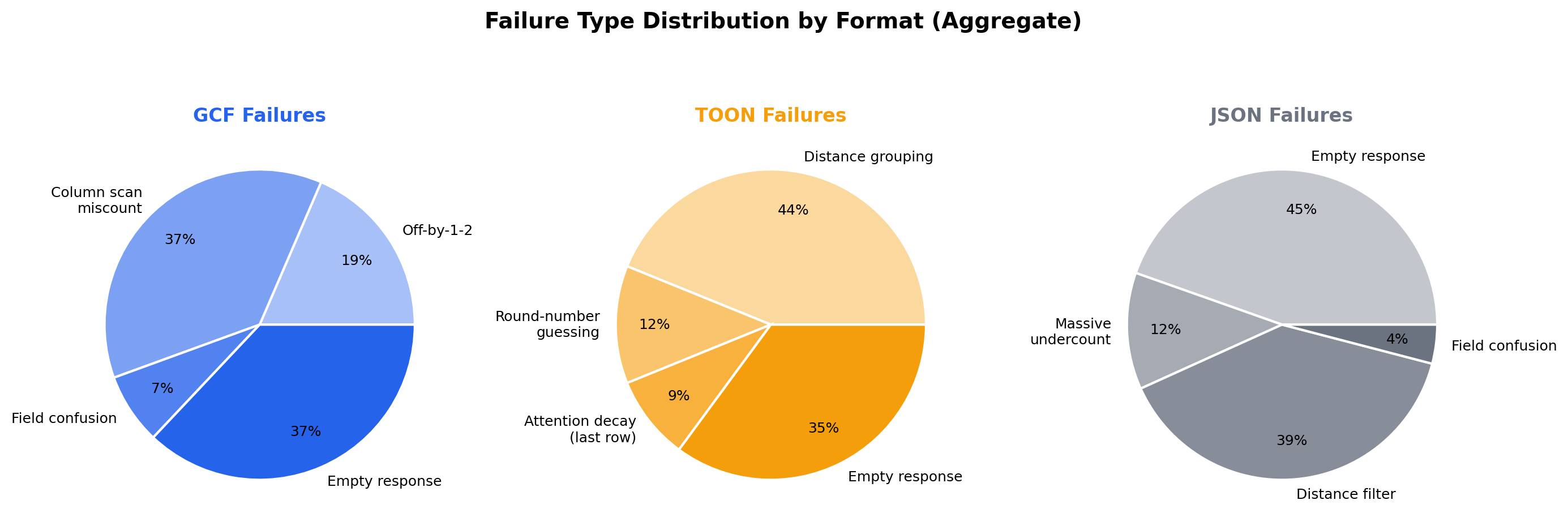
Failure distribution by format
JSON accounts for the most failures overall, driven by GPT-5.5's complete inability to respond (33 empty strings) and universal distance-filtering failures. TOON's failures concentrate on distance grouping and round-number guessing. GCF's failures are sparse and small.
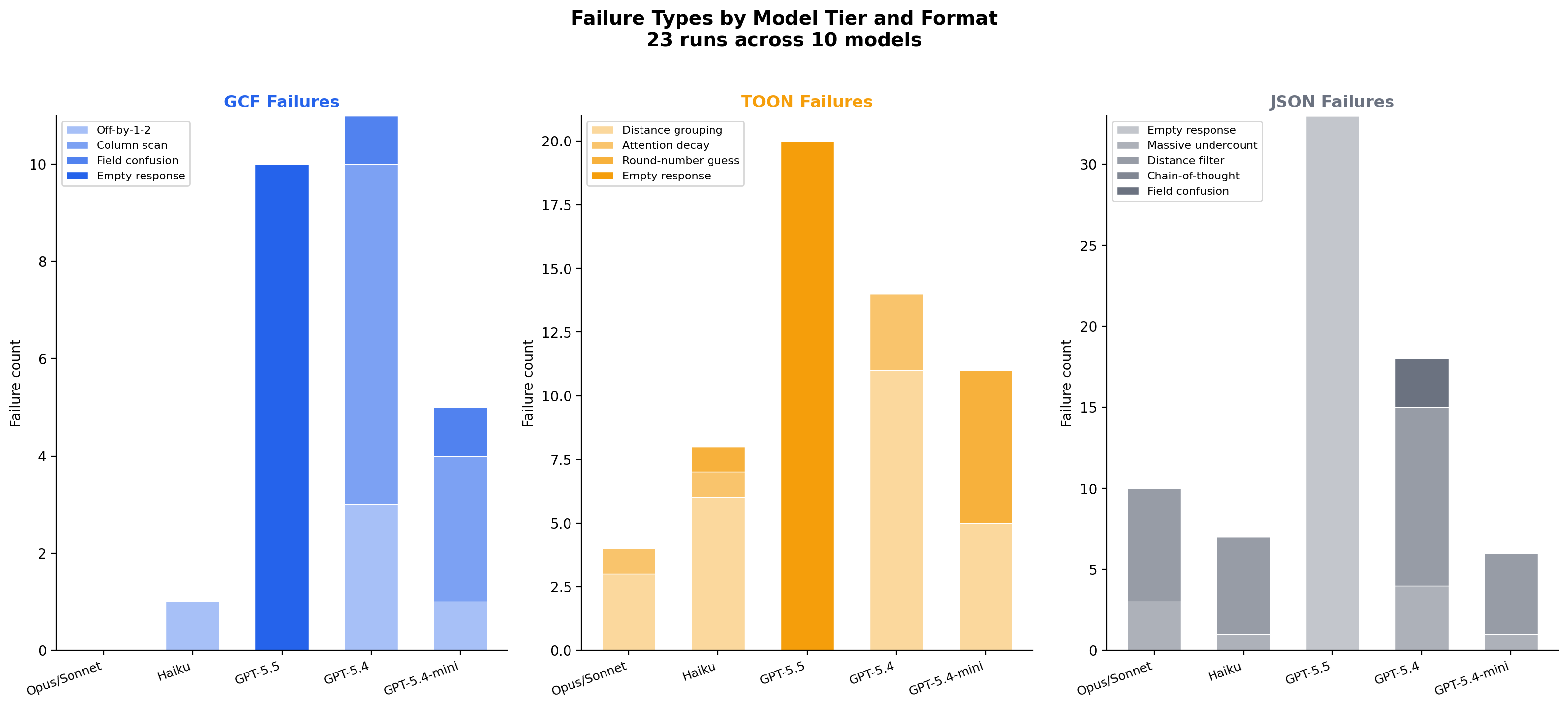
Failures by model tier
Each model tier has a distinct failure signature. Opus/Sonnet never fail on GCF. GPT-5.5 fails on all formats due to context overwhelm at 53k tokens. GPT-5.4's GCF errors are deterministic (same wrong number every run), suggesting a tokenizer-level parsing difference rather than a comprehension problem.
| Model | GCF failure mode | TOON failure mode | JSON failure mode |
|---|---|---|---|
| Opus/Sonnet | None | Off-by-2 extended_count; last_symbol_kind wrong (attention decay at row 500) | Undercounts (356 vs 500); 143-line chain-of-thought enumeration, still wrong answer |
| Haiku 4.5 | None | Distance grouping (100, 200, 214 vs 166); last_symbol_kind wrong | Undercounts; distance filter failures |
| GPT-5.5 | Empty strings (context overwhelm at 53k input tokens) | Empty strings; distance grouping failures | Returns nothing on most questions (53k tokens of repeated field names overwhelms attention) |
| GPT-5.4 | Deterministic: edge_count=198, function_count=84 every run | Distance grouping wildly inconsistent (169, 229, 200 vs 166); round-number guessing | symbol_count 326-404; massive undercounts everywhere |
| GPT-5.4-mini | Same as 5.4 (198, 84) plus larger misses (250, 100) | Worst distance grouping (26, 28 vs 166); defaults to round-number guessing | 300 vs 500 symbol_count; consistent failure across all question types |
GCF failures on Claude are near-zero. GCF failures on OpenAI are deterministic and repeatable (same wrong number every run), suggesting a tokenizer-level parsing difference rather than a comprehension issue.
Mechanistic explanation: tokenization
The tokenizer analysis provides the mechanistic link between format choice and these failure patterns:
- GPT-5.4's deterministic errors (always 198, always 84): GPT-4/4o's tokenizer merges
"id":,"name":,"type":,"value":with the opening quote on every row (30% merge rate across 43 tokenizers). This creates a consistent token-boundary offset that produces the same parsing error every run. - GPT-5.5's empty responses: at 53K tokens, 81% are structural overhead (repeated field names + braces). The attention mechanism has nothing to attend to except noise.
- JSON distance-filtering failures across all models: filtering by a field value requires attending to 500 positions where
"distance":repeats identically. The model cannot distinguish the 150th occurrence from the 350th using positional encoding alone. - GCF's off-by-1-2 precision errors only: GCF's pipe delimiters are always separate tokens (0.47% merge rate vs JSON's 8.17% across 43 tokenizers), so structure is always parseable. Errors come from misreading numbers in headers, not from failing to find the structure.
- Claude never fails on GCF but fails on JSON: Claude's tokenizer keeps all boundaries clean (0% merge on common fields), giving it an advantage on JSON. But 81% overhead still dilutes attention on counting tasks regardless of boundary clarity.
See Tokenizer Analysis: Part 5 for the full analysis.
Artifacts: What JSON failure looks like in practice
When asked "how many symbols have distance 1 (related)?", the answer is 167. GCF encodes it in the section header: ## related [167]. The model reads it directly.
JSON has no structural grouping. The model must scan 500 JSON objects, filter by "Distance": 1, and count. On two separate runs, Claude Opus (the most capable model on earth) responded by manually enumerating every symbol:
Run 1 (full artifact):
"Let me count precisely by going through the list:1. handler.Response.Notify2. model.SubscribeConfig3. service.PublishOptions...143. store.DispatchConfig
So: 143."
143 lines of output tokens. Wrong answer (expected 167).
Run 2 (full artifact):
"Let me count systematically. The symbols list transitions from Distance 0 to Distance 1 at handler.Response.Notify...1. handler.Response.Notify2. model.SubscribeConfig...119. store.DispatchConfig120. cache.ExecuteOptions -- wait, this is Distance 2.
So: 119."
119 lines. Wrong again (expected 167). Different random payload, same failure mode. The model even caught itself mid-count ("wait, this is Distance 2") and still got it wrong.
This is JSON's structural problem: it forces LLMs to perform manual enumeration at scale, burning output tokens on a task the format should have answered structurally. GCF answers the same question from a 3-character header lookup.
Generation: All Runs
Comprehension measures whether a model can read a format. Generation measures whether it can write one. A format that's readable but not writable (or vice versa) is only half useful. Agent-to-agent communication requires both directions.
GCF validity across all models
GCF achieves 5/5 valid output on every frontier model, with zero prior training. The format didn't exist before we built it, yet models produce decoder-parseable output on first exposure with a 3-line primer.
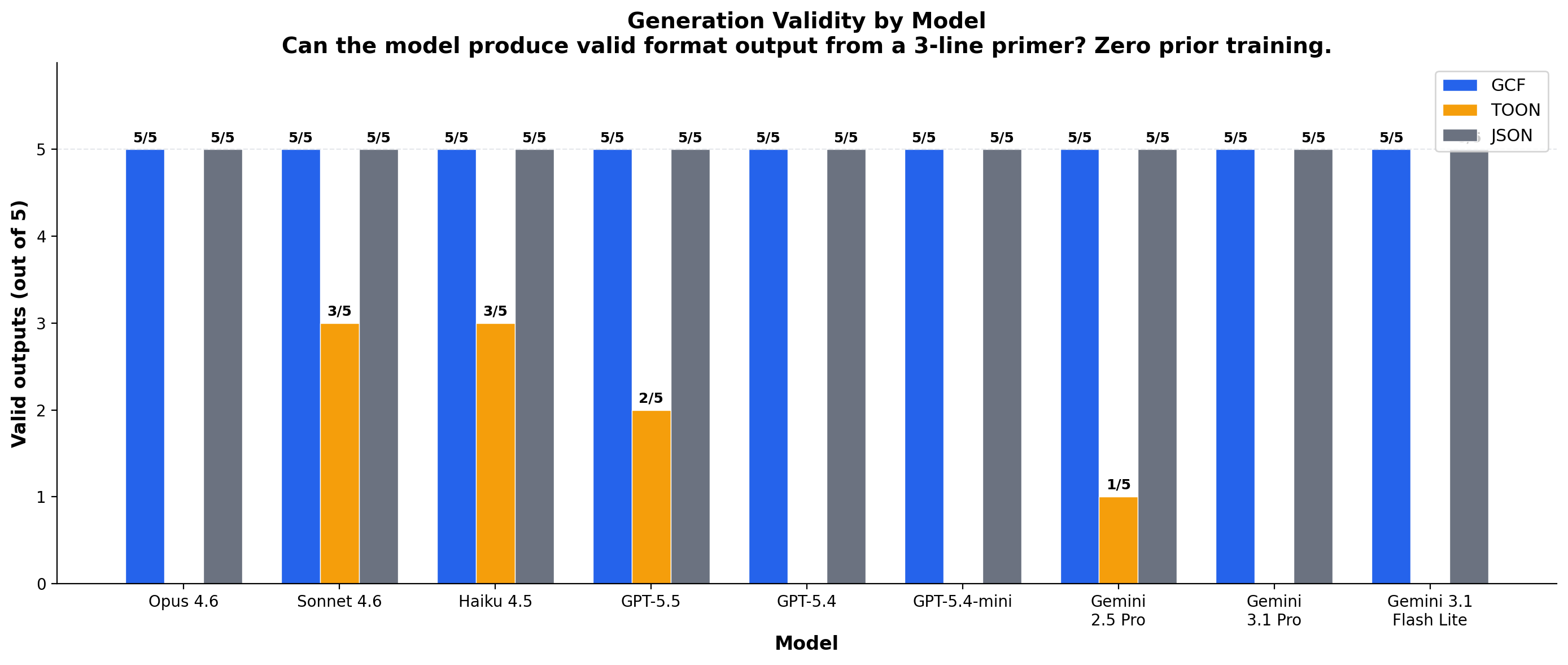
| Model | 5 sym | 10 sym | 20 sym | 50 sym | 100 sym | Score | Runs |
|---|---|---|---|---|---|---|---|
| Claude Opus 4.6 | YES | YES | YES | YES | YES | 5/5 | 2 (zero variance) |
| Claude Sonnet 4.6 | YES | YES | YES | YES | YES | 5/5 | 2 |
| Claude Haiku 4.5 | YES | YES | YES | YES | YES | 5/5 | 2 |
| GPT-5.5 | YES | YES | YES | YES | 4-5/5 | 4-5/5 | 2 |
| GPT-5.4 | YES | YES | YES | YES | YES | 5/5 | 1 |
| GPT-5.4-mini | YES | YES | YES | YES | YES | 5/5 | 2 (zero variance) |
| Gemini 2.5 Pro | YES | YES | YES | YES | YES | 5/5 | 2 (zero variance) |
| Gemini 3.1 Pro | YES | YES | YES | YES | YES | 5/5 | 1 |
| Gemini 3.1 Flash Lite | YES | YES | YES | YES | 4-5/5 | 4-5/5 | 3 |
Three-way comparison
Same data, same prompt structure per format. GCF and JSON use natural-language descriptions ("this symbol is a target"). TOON uses the same natural descriptions, not pre-encoded integers. This is the fair comparison: what happens when you give a model real-world input and ask it to produce structured output?
| Model | GCF | TOON (natural) | JSON | Runs |
|---|---|---|---|---|
| Claude Opus 4.6 | 5/5 | 0/5 | 5/5 | 2 (zero variance) |
| Claude Sonnet 4.6 | 5/5 | 2-3/5 | 5/5 | 2 |
| Claude Haiku 4.5 | 5/5 | 1-3/5 | 5/5 | 2 |
| GPT-5.5 | 4-5/5 | 1-2/5 | 5/5 | 2 |
| GPT-5.4 | 5/5 | 0/5 | 5/5 | 1 |
| GPT-5.4-mini | 5/5 | 0/5 | 5/5 | 2 (zero variance) |
| Gemini 2.5 Pro | 5/5 | 1/5 | 5/5 | 2 (zero variance) |
| Gemini 3.1 Pro | 5/5 | 0/5 | 5/5 | 1 |
| Gemini 3.5 Flash | 3/5 | 1/5 | 3/5 | 1 |
| Gemini 3.1 Flash Lite | 4-5/5 | 0/5 | 4-5/5 | 3 |
| Gemini 2.5 Flash | 2-3/5 | 0-4/5 | 0-3/5 | 3 (output truncation) |
Why TOON fails generation
Every TOON generation failure produces the same error: toon: cannot assign string to int. The model writes target in the distance column. TOON expects 0. The model would need to know, unprompted, that "target" maps to 0, "related" maps to 1, "extended" maps to 2. No model does this because the format gives no structural cue for when a column requires an integer vs a string.

TOON generation heatmap
TOON failure is concentrated on distance-related sizes. Models that pass at 5 symbols often fail at 10+ because the likelihood of hitting the distance encoding problem increases with more symbols. The heatmap shows which models fail at which sizes.
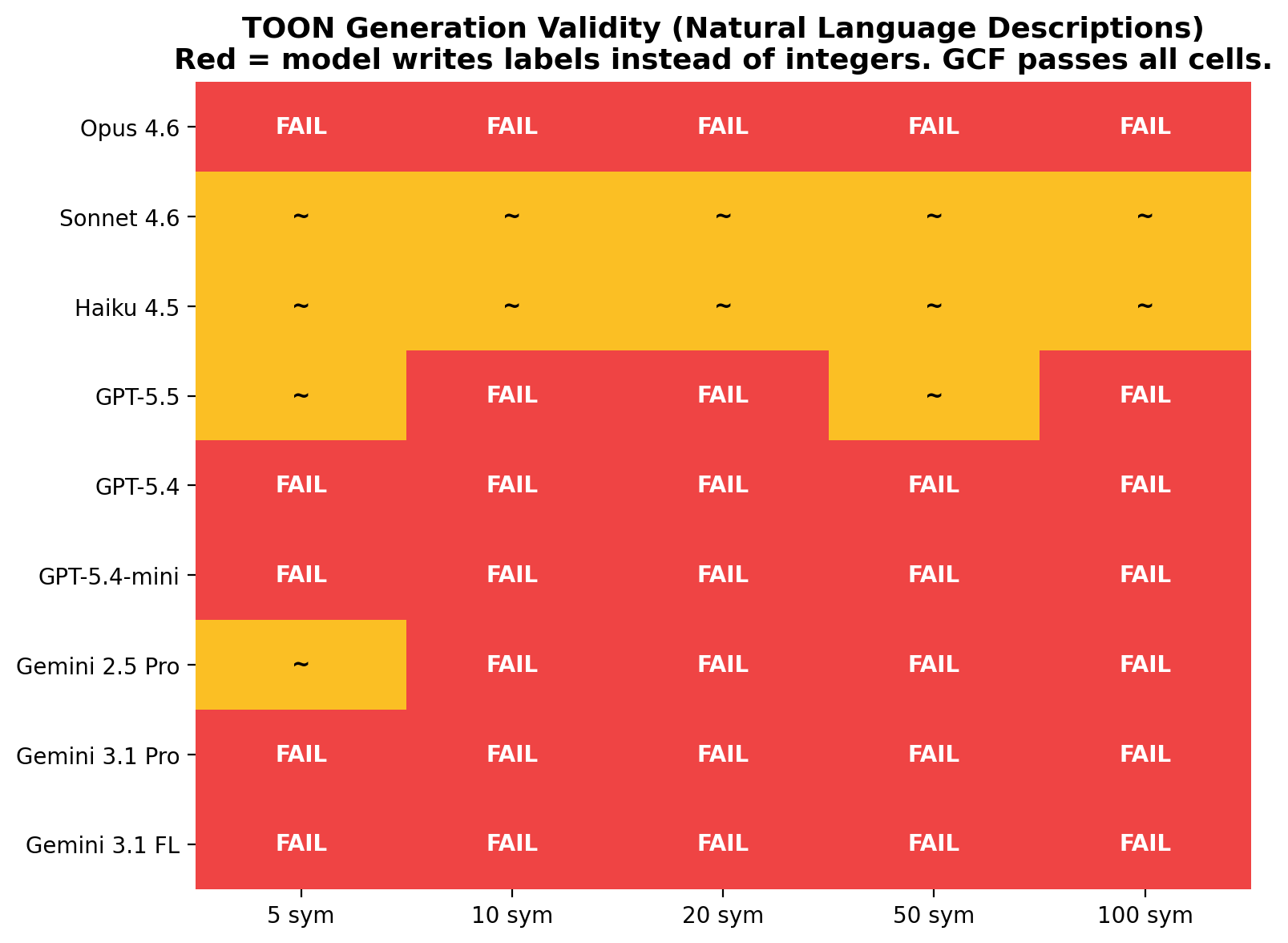
TOON is a fundamentally fragile format
TOON requires special handling by the caller to produce valid results. When given the same natural-language description that GCF and JSON handle without issue, TOON's official decoder rejects the output on 7 of 9 models. The format's flat tabular design encodes semantic categories as integers, forcing an encoding step that no model performs unprompted. This isn't a prompt engineering problem; it's a structural design flaw.
When we explicitly pre-encode distances as integers in the prompt (hand-holding the model through TOON's internal mapping), performance improves on some models but remains inconsistent. Even in the best case, TOON output is 28% larger than GCF.
| Format | Prompt | Valid | 100 sym output | vs JSON |
|---|---|---|---|---|
| GCF | natural labels | 5/5 | 5,984 B | 78% fewer |
| TOON | hand-held (integers) | 5/5 | 8,336 B | 69% fewer |
| TOON | natural labels | 0/5 | - | - |
| JSON | natural labels | 5/5 | 16,121 B | baseline |
GCF is robust. It works with natural-language descriptions, pre-encoded values, and everything in between. The format aligns with how models naturally express grouped data. TOON requires the caller to know its internal encoding and pre-process every categorical field before the model can write valid output. Any time a column encodes a semantic category as an integer, TOON is one prompt change away from producing invalid data.
Output size at scale
Generation cost compounds over a session. Every tool response an agent produces costs output tokens. At 100 symbols, GCF output is 5,984 bytes vs 16,121 for JSON (63% fewer) and 8,336 for TOON with hand-holding (28% fewer). Over a 10-call agent session, this adds up.
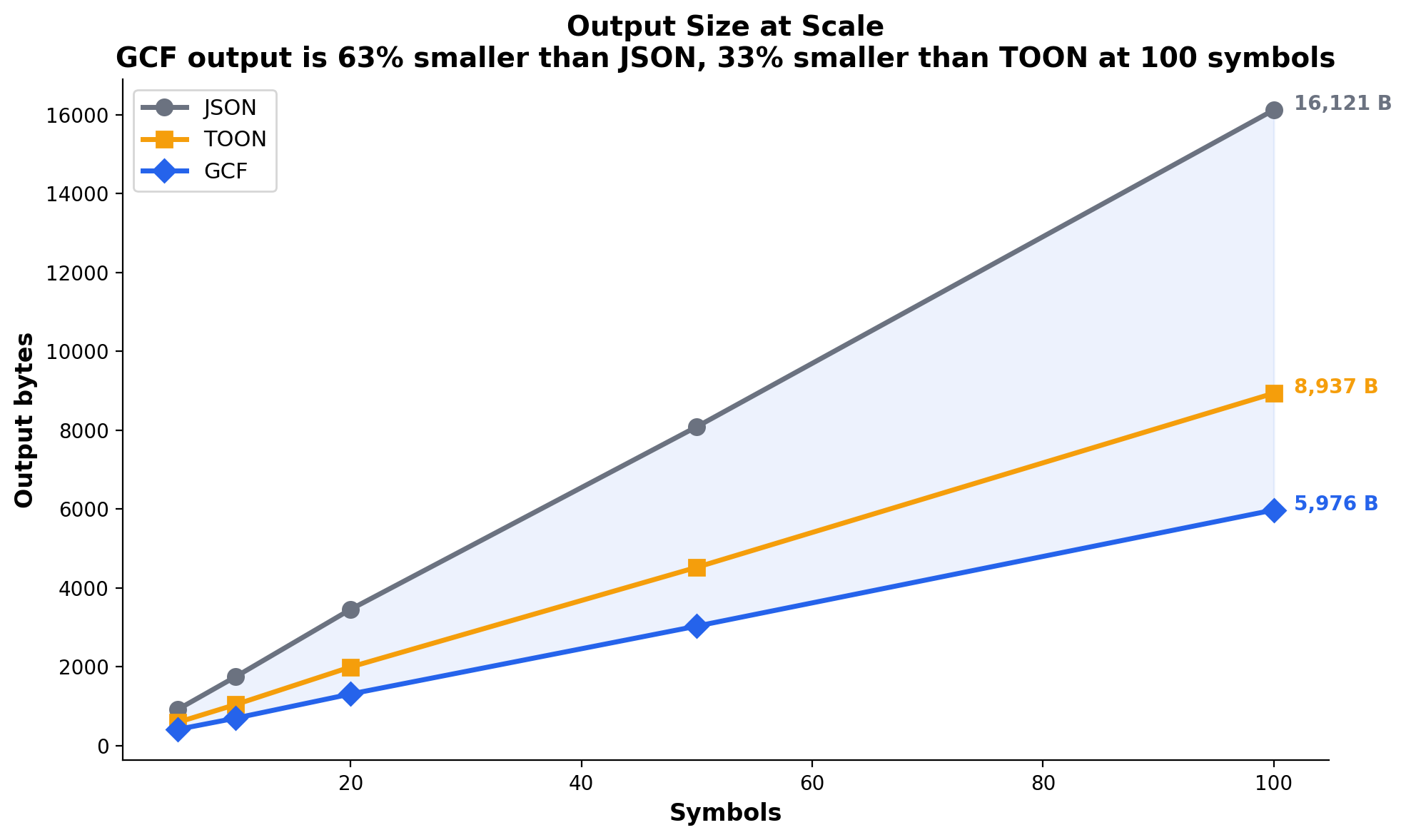
Methodology
The eval was designed to be deterministic, reproducible, and resistant to gaming.
- Scale: 500 symbols/200 edges (graph profile) and 500 orders with nested objects (generic profile) for comprehension; 5-100 symbols for generation; 1000 orders for scale testing. 500 records is the threshold where format differences become visible. At 8 records, everything works.
- Ground truth: 13 extraction questions with deterministic answers computed from the payload. No LLM judge. The correct answer to "how many symbols?" is always exactly the number generated.
- Randomization: Each run generates a fresh random payload with different symbol names and edge distributions. Scores reflect comprehension of the format, not memorization of a fixed dataset.
- Temperature: OpenAI runs used default temperature (non-zero) to reflect real-world usage.
EVAL_TEMPERATURE=0is available for deterministic runs. - Backends: Claude evals via
claude -pCLI with--modelflag. OpenAI evals via chat completions API with exponential backoff on 429s. Google evals via generativelanguage API with retry logic. - Validation: GCF validated through
gcf.Decode(). TOON validated through the official toon-go library. JSON validated throughjson.Unmarshal(). All decoders are real implementations, not regex checks. - Logs: All raw logs in eval/results. Every run is committed.
Reproduce
git clone https://github.com/blackwell-systems/gcf-go
cd gcf-go/eval
# Generic profile comprehension
GOWORK=off EVAL_FORMATS=gcf,json,toon EVAL_BACKEND=cli EVAL_MODEL=haiku EVAL_NUM_ORDERS=500 go test -run TestGenericComprehension -v -timeout 0
# Graph profile comprehension
GOWORK=off go test -run TestComprehension -v -timeout 0
EVAL_BACKEND=openai OPENAI_API_KEY=... EVAL_MODEL=gpt-5.5 GOWORK=off go test -run TestComprehension -v -timeout 0
EVAL_BACKEND=google GOOGLE_API_KEY=... EVAL_MODEL=gemini-2.5-flash GOWORK=off go test -run TestComprehension -v -timeout 0
# Generation (all three formats)
GOWORK=off go test -run "TestGeneration$|TestGenerationTOON|TestGenerationJSON" -v -timeout 0
# Token efficiency (16 datasets)
git clone https://github.com/blackwell-systems/toon-benchmark
cd toon-benchmark
node --experimental-strip-types benchmarks/scripts/token-efficiency-benchmark.ts